Creating a YARA Repository
In this article, I want to explain the real challenges you face when you try to build a YARA rule set for your own project or for your company. Today there are more than +300.000 YARA rules published across over +211 GitHub repositories. When you combine all of them and try to use them as one big rule set, the results are usually disappointing. The false positive and false negative rates are much higher than you expect, mainly because there is no common standard for writing YARA rules (!).
There is also another practical problem. Have you ever tried to compile 300.000 rules into a single YARA file and then scan a file larger than 200 megabytes? If you try, you will immediately notice how slow and unstable the process becomes. At this point, you must make sure that your entire rule set is high quality, unique, and tested before you use it in real scans. Otherwise, a single scan can take more than thirty minutes.
The YARA engine and the Aho-Corasick algorithm allow extremely fast string matching, but this speed does not help when the rules themselves are poorly written. Many rules on the internet contain weak conditions, unnecessary patterns, or mistakes made by analysts. Because of this, building a strong and reliable rule set requires careful cleaning, testing, and optimization.
Part 1 - Why we need a YARA Repository?
YARA is a very powerful and flexible tool used by security researchers and analysts all over the world to detect malware. YARA rules can describe many different characteristics of a malicious file, and they can be written in great detail to identify specific malware families or behaviours. To write strong YARA rules, you need a good understanding of the YARA syntax and capabilities, and you must also be familiar with the malware landscape and current threats.
When people hear “YARA” they often think only about antivirus or endpoint detection, but YARA has many different use cases:
- Detection
- Identification
- Classification
- Hunting
- Triage
- Config Extraction
Because of all these use cases, the security community needs more and more YARA rules every day.
I use the word “community” on purpose. No company in the world can analyse every piece of malware alone or write detection rules for all of them. Many rules are written by independent researchers, and because of that, they are often shared publicly so everyone can benefit from them.
So what creates this need for a large and reliable YARA rule repository?
- The growing number of malware samples: The number of malware families and variants increases every day. There is no universal system that can classify all malware correctly, detect all new versions, or extract every configuration automatically. Because of this, we rely on scanning tools like YARA and constantly updated signatures to identify the files we collect.
- Packers and Obfuscators: Every year, new packers and protection tools appear that encrypt, packs, or FUD malware to avoid detection. This makes static detection much harder. In many cases, we must write static unpackers to extract configurations. If static unpacking is too complex, we run the malware in an online sandbox (like Threat.Zone) and scan the memory dump with YARA. If we want to control locally, we use local sandboxes and extract process dumps with tools such as pe-sieve then scan those dumps again or directly scan memory with THOR. (Like Amber, Themida, VMProtect and Deoptimizer).
- Sleep Mask: Some malware now runs once, then sleeps until the next command or trigger signal. While sleeping, it encrypts its main malicious payload directly in memory. When needed, it decrypts and runs again, sometimes inside a new process. If we scan memory dumps with YARA during the encrypted state, the malicious part may not be visible and this causes false negatives.
- Position-independent (reflective) PE loaders and in-memory execution: Modern malware often uses reflective loading to run payloads entirely in memory without writing anything to disk. These loaders manually map portable executables in memory and resolve imports by themselves. Because no file is ever created, file based YARA rules cannot detect them. The payload exists only in RAM, so detection requires memory scanning, behavioural monitoring, or YARA rules designed specifically to catch reflective loaders and their in-memory artifacts.
Many analysts cannot create every rule on their own because the number of malware samples and detection needs is simply too large. As I mentioned at the beginning of this article, more than two hundred GitHub repositories contain public YARA rule collections, and together they include more than three hundred thousand rules. Even the best rule sets in the community have serious problems. Some of them slow down your scans because they are not optimized, and many of them increase your false positive rate. When we look at the most well known rule sets in the industry, we can see both their strengths and their limitations.
- YARA Forge: This is one of the best public sources you can find. It combines rules using the YARA Forge tool created by Florian and currently contains
11.418rules. However, many recent stealer and ransomware families are still missing from the collection. - YARA-Rules: This project was created
6years ago by a community of more than 70 people, but it has not received any new rules in the last3years. It contains more than 10.000 rules, but many of them produce a high number of false positives and do not cover modern threats. - Valhalla: Valhalla has more than
23.223high quality rules, and many professional tools such as theirTHOR APT Scanneruse this rule set internally. Only a small part of the rules, around2.705, are available for free. The rest of the rules are commercial, so you cannot use them freely for personal research. - YARAhub: This is a collection of rules submitted to YARAify with TLP:CLEAR classification. It contains
923rules, but less than half of them can be viewed in detail. It is a great resource for hunting current threats, but the dataset is still too small to rely on alone. - Defender YARA: This repository contains rules extracted from the Microsoft Defender’s
mpavbase.vdmandmpasbase.vdmsignature databases. These signatures can be used to build strong rules, but because they are based only on static patterns and do not include behavioral logic, they often produce many false positives and false negatives.
So yes, there are many places where you can collect rules and start building your own repository, but there is a major problem that affects the entire community. Every analyst writes YARA rules in their own personal style because there is no global standard. Another issue is that many public collections reuse rules from other collections but rename them or reorganize them, which creates duplicates. As a result, we end up with many rules that look different but detect the same thing. This makes rule sets inconsistent and difficult to manage, and it shows why we must focus on standardizing the rules we use.
Part 2 - Rule Standardizations
We have a rule standardization problem for several clear reasons:
- Every analyst writes rules in their own style, because there is no common standard that everyone follows.
- The Meta fields and tags inside YARA rules are often used incorrectly or not used at all. This makes it difficult to understand what a rule is trying to detect, and it becomes almost impossible to test the rule on a correct sample.
- Many rules are poorly named. When a rule matches a file, you cannot easily understand what operating system the rule targets, what file format it focuses on, what risk level it represents, or what malware family it belongs to.
- Some analysts forget that YARA conditions run on a regular expression engine. Because of this, they write slow or wrong conditions that cause serious performance issues.
At this point, the YARA Style Guide created by Florian is the most important resource that everyone in the industry should follow (IMO). I have always used this guide when creating my own rule sets and while managing rules at work. When a rule name and its Meta fields follow this style guide, the rule becomes easy to read, easy to understand and easy to test for any analyst.
With this standard, the rule name clearly tells you:
- whether the detection is Malicious, Suspicious or Informational
- what version of the file or malware the rule detects
- which malware family or software product it targets
- and the date when the rule was created or last updated
The Meta fields give even more important context. For rules that detect malicious samples, we always include references and hashes. This allows analysts to compare the detected malware with public sandbox reports or with samples already in their collection, and it helps them notice when a new variant appears. Another common mistake is adding simple ASCII strings in hexadecimal format. If you are not showing a function body or including special characters such as newline or tab, you should keep the string in normal ASCII format. There is no reason to overcomplicate it.
Below is an example rule that follows this structure.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import "pe"
rule INFO_V8_Javascript_Engine_Jul_11 : INFO JS COMPILER {
meta:
description = "This rule detects files compiled by the V8 Javascript engine."
author = "@brkalbyrk7"
date = "2024-07-10"
sharing = "TLP:CLEAR"
tags = "info,javascript,compiler"
reference = "https://github.com/v8/v8"
os = "multi"
category = "Info"
strings:
$mlin1 = "_ZN2v88internal" wide ascii
$mlin2 = "_ZNK2v88internal" wide ascii
$mlin3 = "_ZNSt8_Rb_tree" wide ascii
$mlin4 = "V8_TORQUH" wide ascii
$mlin5 = "_ZTVN2v88internal" wide ascii
$mlin6 = "_ZN2v84base" wide ascii
condition:
uint16(0x02) == 0xC0DE or pe.exports(/internal@v8@@@/) or (2 of ( $mlin* ) )
}
Or,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import "math"
import "pe"
rule MAL_EXE_Dridex_PE_Hollowing_Jul_23 : EXE MAL TROJAN
{
meta:
description = "This rule detects Dridex samples that use PE Hollowing technique."
author = "@brkalbyrk7"
date = "2025-01-01"
sharing = "TLP:CLEAR"
tags = "exe,trojan,malicious,pe_hollowing"
sample = "e30b76f9454a5fd3d11b5792ff93e56c52bf5dfba6ab375c3b96e17af562f5fc"
reference = "https://www.virustotal.com/gui/file/e30b76f9454a5fd3d11b5792ff93e56c52bf5dfba6ab375c3b96e17af562f5fc"
os = "windows"
category = "Malware"
strings:
$mw1 = "MFC42.DLL" ascii fullword
$mw2 = "XPVSS" ascii fullword
$mw3 = "__CxxFrameHandler" ascii fullword
$mw4 = "__except_handler3" ascii fullword
$mw5 = "CWordAutomationDlgAutoProxy" ascii fullword
$mw6 = "WordAutomation.Application" ascii fullword
condition:
all of ($mw*) and math.entropy(pe.sections[pe.section_index(".rsrc")].raw_data_offset,pe.sections[pe.section_index(".rsrc")].raw_data_size) >= 7.9
}
Is it enough?
Part 3 - Performance and Optimization Problems
Of course, standardizing the rules alone does not solve all of our problems. The way a rule is written has a huge impact on our average scan time and on how well we can detect malware. To understand this better, we can look at a simple example and see what kinds of performance and optimization issues can appear.
Imagine we are trying to identify the format of a file in three different ways. If the file reached our device through another dropper, or if it was packed with a packer and we could not extract any readable strings, then our rule will fail. In this case, the file may only exist in memory inside another running process. If we do not take a memory dump or extract the memory regions of all loaded PE/DLL files, we will never see the real file as a static sample. That means our static YARA rule will not detect it.
The opposite situation is also possible. Some malware exists only in memory during execution and never writes a file to disk. In this case, we can detect it in memory with a memory scan, but we will not find anything if we try to detect it statically. The static sample simply does not exist. This is why the writing style and structure of YARA rules matter. Good rules must work in different environments and must consider both static and memory based detection paths. If we ignore this, our rules may look correct, but they will fail in real world conditions. An example of this situation:
When file type not specified correctly-> (except Memdump)
1
2
3
4
5
6
condition:
(
uint16(0) == 0x5a4d // MZ marker
and uint32(uint32(0x3C)) == 0x00004550 // PE signature at offset stored in MZ header at 0x3C
or uint16(0) == 0x457f // ELF marker
)
So, does this fully solve our problem? Of course not. There are many other issues that affect detection quality and scan performance. Most of these problems can be addressed by following Florian’s work in the YARA Performance Guidelines , which is one of the most useful resources for anyone who writes YARA rules.
However, it is important to understand that writing a high performance rule is not only about the quality of the regex engine or the search engine inside YARA. Performance comes from the way you design the rule itself. The rule writer has full control over how heavy or light the matching process becomes. If the rule contains unnecessary checks, weak atoms, or heavy conditions, it will slow down scanning, even if the YARA engine is fast. In other words, performance starts with the analyst, not with the tool. But the situation changes completely when we want to scan files using much larger rule collections.
YARA works by breaking each rule into very small parts called atoms (4-byte substrings). These atoms are short byte sequences that must appear in the file if the rule is true. YARA puts all these atoms into an Aho-Corasick search engine, which can scan a file very quickly in one pass. When this search engine finds an atom in the file, YARA then checks the full string and the rule condition to confirm the match. This method lets YARA test many rules at the same time while staying fast and accurate.
If we look at this in more detail, YARA scans a file in four basic steps.
- When you compile YARA rules, YARA reads every string inside the rules and breaks each string into very small parts called atoms. YARA chooses atoms that give the best chance of finding the real pattern while avoiding unnecessary work. Even when a rule has modifiers such as wide or nocase, YARA still chooses atoms that match all allowed versions of the string. At the end of this stage, YARA has a large collection of atoms that represent all rules.
- YARA builds an Aho-Corasick automaton with all extracted atoms. This automaton is a structure that can find many patterns at the same time. It reads the file once from beginning to end and reports every atom that appears in the file. This allows YARA to handle hundreds of rules and thousands of strings without slowing down. Atom hits found in this stage are only possible matches. They tell YARA where to look more closely.
- When the automaton reports an atom hit, YARA checks the full string. Each string inside a YARA rule is converted into a small piece of bytecode during compilation. This bytecode explains exactly how the full string should be validated. It contains information about literal bytes, jump instructions, unicode handling, case rules and many other details. YARA uses its bytecode engine to confirm whether the whole string truly matches the file. This prevents false positives that would happen if YARA trusted atoms alone.
- After verifying string matches, YARA checks the condition section of the rule (Please do not forget this -> YARA checks the condition after atomic matches). This condition can include string counts, file metadata, arithmetic expressions, logical operators and many other elements. The rule is reported as matched only if the condition is true.
Now that we understand the overall picture, we can look at some concrete situations that create performance problems. In the next section, we will go through real examples of rule patterns, conditions and design choices that slow down scans or add noise, and we will see how to rewrite them in a more efficient way.
When you write nested for loops in YARA, the engine must evaluate each loop combination separately. If you have a loop inside another loop, and that loop is inside yet another loop, YARA needs to check every possible combination of matches. This creates exponential growth in operations.
For instance, if string $a appears 100 times in a file, a single loop checks 100 positions. But two nested loops checking the same string would create 10,000 checks (100 x 100). Three nested loops would create 1,000,000 checks (100 x 100 x 100). This quickly becomes extremely slow.
Too many loop inside each other
1
2
3
4
5
6
7
rules for_loop {
strings:
$a = {00 00 01}
condition:
for all i in (1..#a) : (@a[i] < 10000)
}
The Aho-Corasick algorithm depends on atoms. YARA works best when these atoms are at least 4 bytes long because shorter atoms appear too frequently in files, causing performance problems. When you define strings shorter than 4 bytes, YARA cannot extract a good atom for fast scanning. Instead, it must check almost every position in the file, which is extremely slow. The engine essentially falls back to a slower matching method because it cannot use its optimized search algorithm effectively.
Using short strings as variables (4 bytes)
1
2
3
4
5
6
7
rule test {
strings:
$a = {DIE}
condition:
#a > 1000
}
YARA evaluates conditions from left to right. In this example, the condition order causes performance problems because YARA first searches for all six strings in the file, then calculates the entropy of the resource section, and finally checks if the file is a PE file. The problem is that YARA does expensive operations before cheap ones. Checking uint16(0) == 0x5a4d (the PE magic bytes) is extremely fast because it only reads 2 bytes at the file start. Calculating entropy is much slower because it must process the entire resource section. Searching for all six strings is the slowest operation. If the file is not even a PE file, YARA wastes time searching for strings and calculating entropy before discovering the file does not match.
Incorrectly ordered conditions
1
2
3
4
5
6
7
8
9
10
strings:
$mw1 = "MFC42.DLL" ascii fullword
$mw2 = "XPVSS" ascii fullword
$mw3 = "__CxxFrameHandler" ascii fullword
$mw4 = "_except_handler3" ascii fullword
$mw5 = "CWordAutomationDlgAutoProxy" ascii fullword
$mw6 = "WordAutomation.Application" ascii fullword
condition:
all of ( $mw* ) and math.entropy(pe.sections[pe.section_index(".rsrc")].raw_data_offset, pe.sections[pe.section_index(".rsrc")].raw_data_size) >= 7.9 and uint16(0) == 0x5a4d
String modifiers significantly impact YARA’s performance. The nocase modifier forces YARA to generate atoms for every possible case combination, multiplying the search patterns exponentially. Using ascii wide together doubles the atoms since YARA must create separate patterns for both encodings. The fullword modifier helps reduce false positives by matching only complete words rather than partial strings. Always use the most specific modifiers needed for your detection to avoid unnecessary performance overhead.
Not paying attention to string definitions (nocase ascii wide)
1
2
3
4
5
6
7
8
9
10
$s1 = "cmd.exe" // ascii
$s2 = "cmd.exe" ascii // (ascii only, same as $s1)
$s3 = "cmd.exe" wide // (UTF-16 (Unicode) only)
$s4 = "cmd.exe" ascii wide // (both ascii and UTF-16) two atoms will be generated
!! $s5 = "cmd.exe" nocase // (all different cases, e.g. "Cmd.", "cMd.", "cmD." ..)
!! $re = /[Cc]md\.exe/ // use the regex in case of need
// checks non-alphanumeric characters surrounded by alphanumeric characters
$na1 = "domain" fullword // not matches www.domain.com
$na2 = "domain" // matches www.domain.com check this out
At the same time, do not be afraid to write more advanced rules. If you cannot create a reliable rule by using only strings, you should move one step deeper and look at the code itself. Use a disassembler and try to find a function or code pattern that is unique to that malware family. Once you identify such a function, you can build a rule that targets this specific behaviour instead of generic strings. These kinds of rules are harder to create, but they are usually much more stable, harder for attackers to evade, and far more useful in long term hunting.
Feel free to write more advanced rules.
1
2
3
4
5
6
7
8
9
10
11
12
13
Accessing data at a given position: uint16(0) == 0x5A4D
Check the size of the file: filesize < 2000KB
Set of strings: any of ($string1, $hex1)
Same condition to many strings: for all of them: (# > 3)
Scan entry point: $value at pe.entry_point | at 0
Match length: !rel[1] == 32
Search within a range of offsets: $value in (0..100)
While YARA modules like PE, ELF, and dotnet provide convenient functions, they add processing overhead. For simple checks, direct byte verification is much faster than importing entire modules. For example, checking if a file is a PE by reading the MZ header (uint16(0) == 0x5A4D) is significantly faster than using pe.is_pe because it avoids loading the entire PE module.
However, this approach has tradeoffs. The manual condition below checks for .NET executables:
Don’t hesitate to import libraries in large projects.
1
2
3
4
5
6
7
condition:
uint16(0) == 0x5A4D
and (uint32(uint32(0x3C)) == 0x00004550)
and ((uint16(uint32(0x3C)) + 24) == 0x010B)
and uint32(uint32(0x3C) + 232) > 0
or ((uint16(uint32(0x3C)) + 24) == 0x020B)
and uint32(uint32(0x3C) + 248) > 0
The rule above generates the same result with this condition:
1
2
condition:
dotnet.is_dotnet == 1
Let us assume that up to this point you have written every rule with performance in mind.
Still not fast enough?
From this point on, any remaining slowdown usually comes from YARA itself, not from the way you wrote your rules. The main reason is the regular expression engine that YARA uses. The Avast team noticed this limitation and created an improved engine called YARAng, which uses SIMD registers on Intel processors to compare many atomic bytes at the same time. They also replaced YARA’s built-in regex engine with Hyperscan, a high-performance regex library developed by Intel.
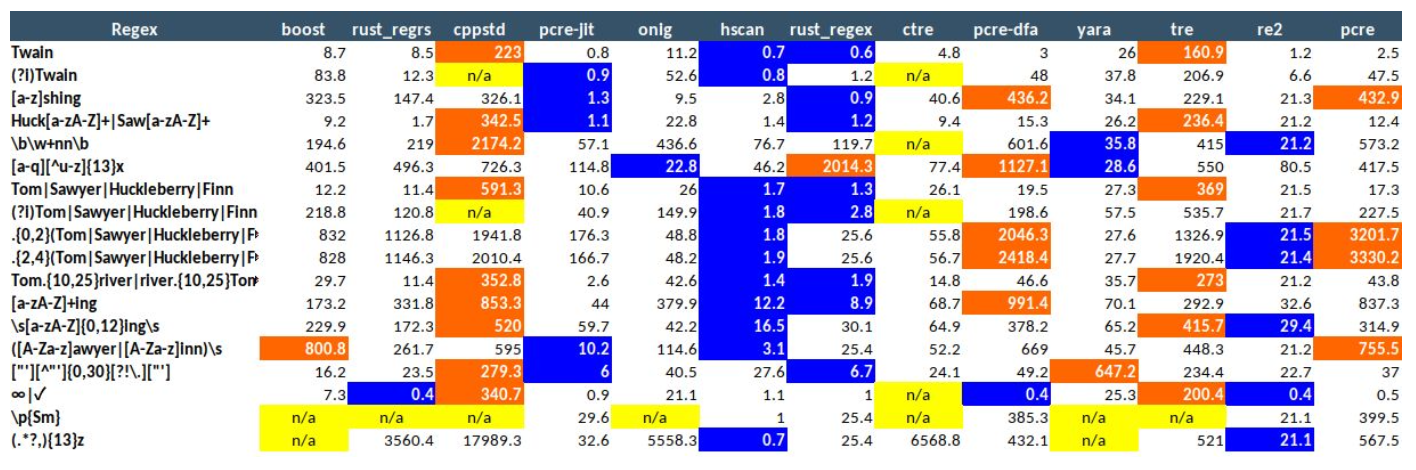
By using Hyperscan instead of the default engine, they were able to remove many of the bottlenecks that come from YARA’s original matching system. If you look at the regex performance table below, you can clearly see the difference between YARA and Hyperscan.
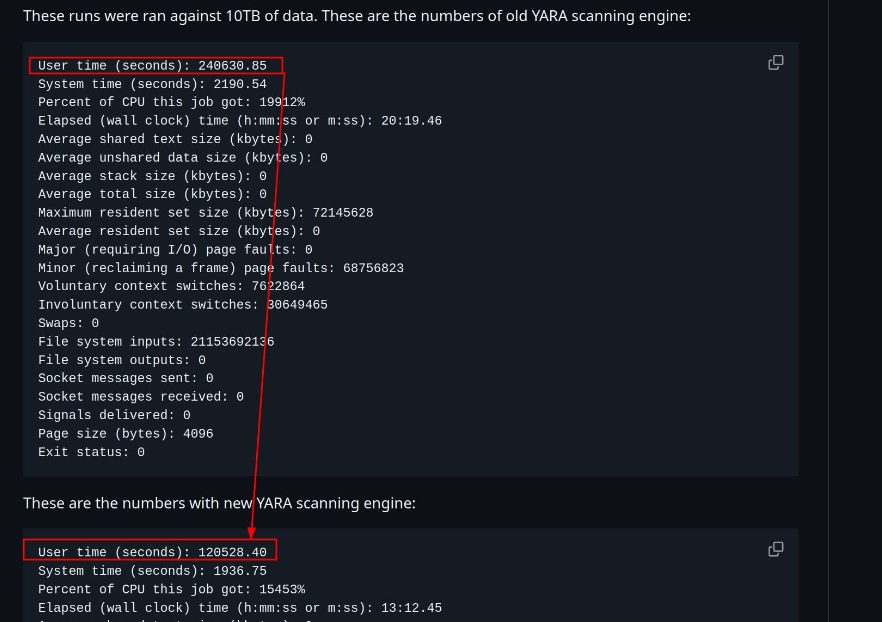
As a response to many of YARA’s performance problems, the Virustotal team rewrote the engine in Rust last year and released yara-x. However, even with yara-x, some issues still continue. For example, when I scan a 350 MB file with my own collection of around 35,000 unique YARA rules, the scan still takes almost 2 minutes. Now imagine you have a malware warehouse of 10 terabytes and you want to scan your entire dataset with the same rule set. In this case, the difference becomes even more important. With normal YARA, the estimated scan time is 240,630.85 seconds. When the same scan is done with YARAng, the time drops to 120,528.40 seconds. This shows how much improvement a high performance regex engine can bring when you work with very large rule sets and huge malware collections.
SIMD makes pattern matching much faster by letting the CPU compare many bytes in parallel instead of checking each byte one at a time. A normal loop would compare every position separately, but SIMD instructions load a whole block of data into a vector register and perform a single instruction that checks all bytes at once. For example, in SSE you can load 16 bytes with movdqu xmm0, [rdi] and then compare them all to a target value using pcmpeqb xmm0, xmm1, which instantly returns which of the 16 positions match. This parallel design is the reason engines like Hyperscan can test hundreds of atoms or patterns in only one CPU cycle, making them far faster than classic YARA’s atomic bytes checking.
movdqu xmm0, [rdi] ; load 16 bytes pcmpeqb xmm0, xmm1 ; compare all 16 bytes at once pmovmskb eax, xmm0 ; produce a mask of matching positions
So what?
Part 4 - Rule Submission Automatization
At this point we have standardised our rules and improved their performance. The next step is to build automation that can add every new rule into the workflow and test our existing rules without manual effort.
I will not share all of my GitHub workflows here, maybe I will publish a fully automated project in the future.
By adding tags to our rules, we usually understand the main purpose of each rule and what it is designed to detect. But not every YARA rule on the internet comes with a proper tag. Because of this, we separate our rules into three main folders called INFO, SUSPICIOUS and MALICIOUS. Then we name each rule file in a way that works as a tag. This makes it simple to understand the detection level and the goal of the rule just by looking at the file name. Here are some examples of the tags we use:
- INFO - framework, library, packer, network
- SUSPICIOUS - anomaly, destruction, evasion, obfuscation, infosteal
- MALICIOUS - OS (windows, linux, macos) -> Type (apt, botnet, rat, shellcode, stealer, downloader)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
SOURCE_DIR (Path.cwd())
│
├── malware/
│ ├── windows/
│ │ ├── ... .yar files
│ │
│ ├── linux/
│ │ ├── ... .yar files
│ │
│ ├── macos/
│ │ ├── ... .yar files
│ │
│ └── (other malware-related .yar files)
│
├── suspicious/
│ ├── ... .yar files
│
├── info/
│ ├── ... .yar files
│
└── compiled/
└── python/
├── malware/ compiled .yar (binary) rules
Before we add any new rule into our separated rule sets, we pass each rule through four different steps.
1- Has the relevant rule been created by the team before | Rule Deduplication?
The first step is to check whether the rule already exists in our collection. We do this by using a simple Python script that creates a hash only from the strings inside the rule. If another rule in our repository contains the same string set, we treat it as a duplicate. This helps us avoid adding the same rule multiple times, especially because many public rule sets reuse each other’s rules with different names or personal tags added by analysts.
You may wonder if two different rules could produce the same hash because they use the same strings but a different condition. This is possible in theory, even if I have never seen it happen in practice. Because of this, we also add an extra check to compare the conditions and make sure that the two rules are not only string duplicates but also logically identical.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
import sys
import hashlib
from pathlib import Path
from yaramod import Yaramod, Rule
baseline_names: set[str] = set()
baseline_hashes: dict[str, str] = {}
def compute_rule_hash(rule: Rule) -> str:
h = hashlib.sha256()
for s in rule.strings:
h.update(s.text.encode())
h.update(rule.condition.text.encode())
return h.hexdigest()
def load_baseline(file_path: Path) -> None:
y = Yaramod()
ruleset = y.parse_file(str(file_path))
for rule in ruleset.rules:
baseline_names.add(rule.name)
baseline_hashes[compute_rule_hash(rule)] = rule.name
def check_new_rules(file_path: Path) -> None:
y = Yaramod()
ruleset = y.parse_file(str(file_path))
for rule in ruleset.rules:
r_hash = compute_rule_hash(rule)
same_name = rule.name in baseline_names
same_hash = r_hash in baseline_hashes
if same_name and same_hash:
original = baseline_hashes[r_hash]
print(f"[duplicate-both] {rule.name} already exists with same name and same content as {original}")
continue
if same_name and not same_hash:
print(f"[same-name] {rule.name} already exists in baseline, but CONTENT differs")
continue
if same_hash and not same_name:
existing = baseline_hashes[r_hash]
print(f"[same-hash] {rule.name} is IDENTICAL to baseline rule {existing}")
continue
print(f"[new] {rule.name} is NOT in baseline")
def main() -> None:
if len(sys.argv) != 3:
print("Usage: python dedup.py <baseline.yar> <new_rules.yar>")
sys.exit(1)
baseline = Path(sys.argv[1])
new_rules = Path(sys.argv[2])
load_baseline(baseline)
check_new_rules(new_rules)
if __name__ == "__main__":
main()
Now if you create two different rules and test them with this method, you will clearly see the result.
a.yar
1
2
3
4
5
6
7
8
9
10
11
12
13
14
rule TEST_A {
strings:
$a1 = "hello1"
$a2 = "hello2"
condition:
all of them
}
rule TEST_B {
strings:
$a = "hello2"
condition:
$a
}
b.yar
1
2
3
4
5
6
7
rule TEST_C {
strings:
$c1 = "hello1"
$c2 = "hello2"
condition:
all of them
}
When you try to add the new rule into b.yar, the system will detect that the same condition already exists somewhere in the rule set.
1
2
❯ python dedup.py testa/a.yar testb/b.yar
[same-hash] TEST_C is IDENTICAL to baseline rule TEST_A
2-What is the quality of the rule? | yaraQA
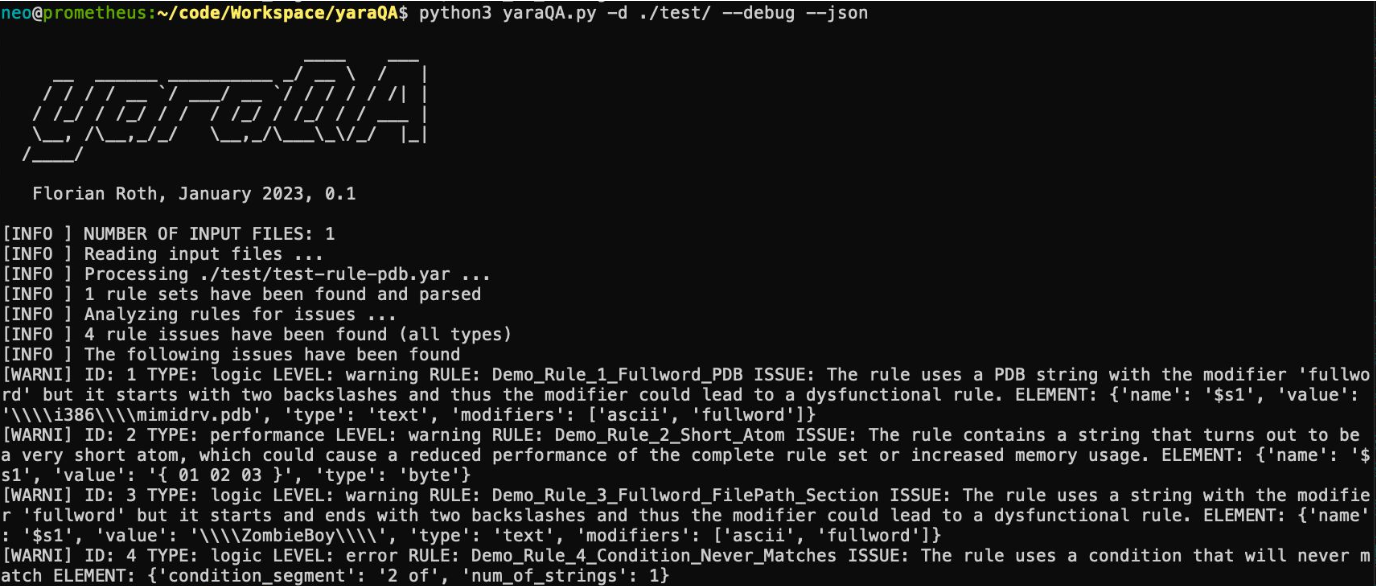
To quickly test the quality of a YARA rule, you can first pass it through Florian’s yaraQA tool or simply run YARA itself against the rule. This allows you to detect basic problems such as syntax errors, incorrect structure, or obvious performance issues before you add the rule into your main repository. Running this kind of quick validation step helps you catch broken or heavy rules early so they do not slow down your scans or cause confusion later.
3- What is the f/p ratio of the rule against benign files?
At this stage you need to check whether your YARA rule matches any benign file on the internet and what its false positive rate looks like. For this purpose there is a very useful GitHub App from Virustotal called YARA-CI. After you install this app on your repository, every time you push a new rule it automatically tests that rule against the NSRL database from NIST. In simple terms this database contains hashes of known good software such as remote management tools, system administration utilities and common Windows or Linux binaries.
When YARA-CI runs your rule against this benign dataset, it shows you if your rule accidentally matches any of these legit files. This way you can see early if your rule would trigger on a remote monitoring tool, a backup agent or a normal operating system binary and you can fix the rule before it reaches production.
You can download and search the NSRL database locally. But you need enough storage around 150GB. The NSRL is a project by NIST to collect and catalogue known software applications. The idea is to build a large set of file profiles (like cryptographic hashes, file names, version information, etc.) from legitimately distributed software/operating systems, commercial applications, games, mobile apps, updates and patches.
4- How many malware can the rules we write detect? | Rule Precision/Detection Rate
If you are wondering how to test your rules after you build your rule list or add a new rule into the system, there are several good options besides small local tests. One of the most useful approaches is to run your rules against existing malware warehouses that already contain classified samples. This lets you see whether each rule really detects the malware family or the informational pattern it was written for.
There are a few public services you can use for this. Platforms such as Unpacme, Hybrid Analysis and YARAify allow you to run your YARA rules against large collections of already analysed samples. By doing this, you can measure how often your rule hits the correct malware family, how well it generalises to other variants and whether it stays quiet on unrelated samples. This gives you a clear view of the real detection power of your rule, not only on your own samples but also in a broader malware ecosystem.
I do not mention VT, Joe or Any.run because they’re paid.
Another option is to build your own local malware warehouse by downloading publicly available, already classified malware datasets. This gives you full control over the samples and allows you to test your rules without relying on external services. For this purpose there is an excellent solution created by CERT PL. By using ursadb together with the mquery tool, you can build a powerful local search engine for your warehouse. Once your dataset is indexed, you can run your YARA rules directly on your own collection and see how they perform. This setup lets you test detection quality, measure coverage and experiment freely with your rules in a controlled environment.
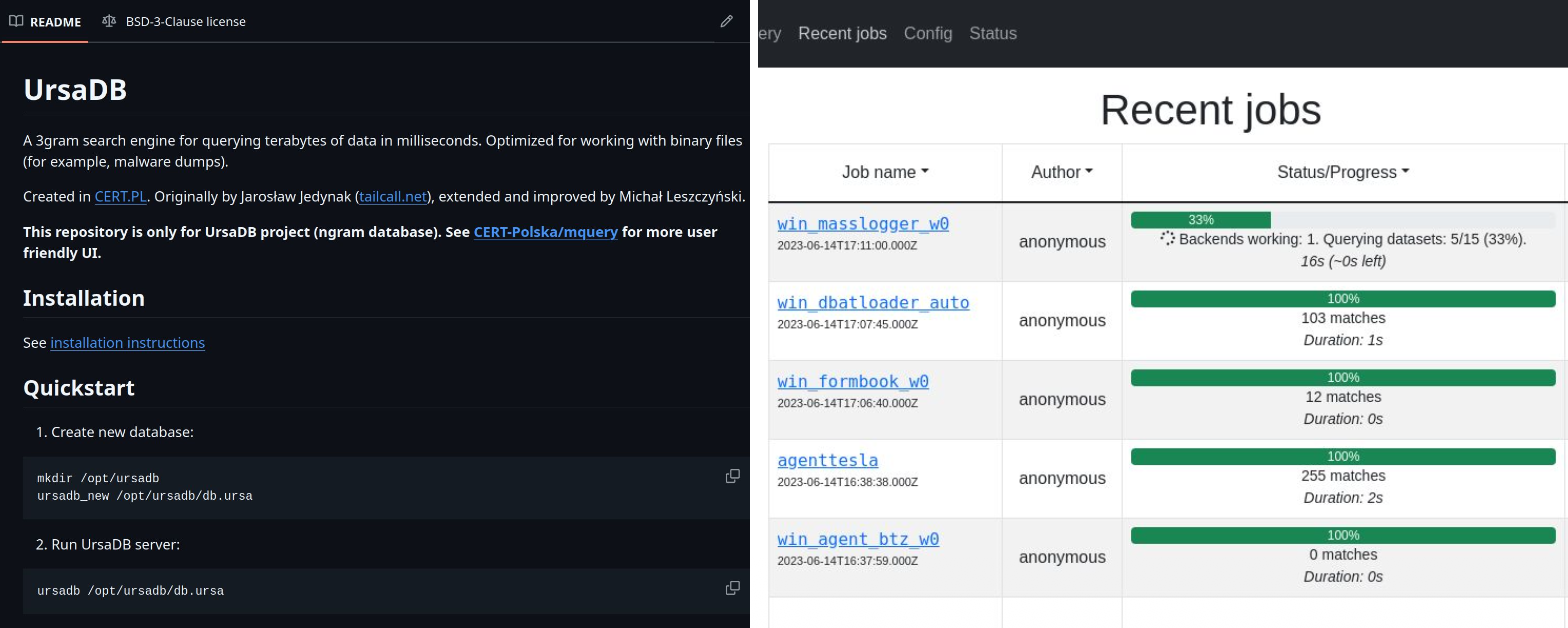
By fully automating these four steps and connecting them to your GitHub Actions, you can make sure that every new rule set is added into the system without problems. Your false positive rate will drop significantly, and your scans will run much faster than before. In the end you get a cleaner rule repository, more reliable detections and a YARA workflow that is maintainable even as your rule count and malware corpus continue to grow.
On your final dataset, you can perform the actual scans using simple Python scripts. This lets you test your entire rule set on real samples in a controlled and repeatable way, and it gives you a clear view of how your rules behave in practice. For this final step, you need to compile all of your rules in a format that clearly tells you two things for every match: which malware family it belongs to and what information level the rule represents, such as informational, suspicious or malicious.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
import yara
from pathlib import Path
SOURCE_DIR = Path.cwd() # "yara-rules"
COMPILED_DIR = SOURCE_DIR / "compiled" / "python"
print(COMPILED_DIR)
compile_list = ["malware", "suspicious", "info"]
def create_dir_structure(compiled_dir: Path, original_path: Path) -> None:
path = Path(original_path)
rule_dir = path.parent.name
try:
if path.parents[1].name == "yara-rules" or rule_dir == "malware":
rule_dir = ""
except IndexError:
rule_dir = ""
target_dir = compiled_dir if rule_dir == "" else compiled_dir / rule_dir
target_dir.mkdir(parents=True, exist_ok=True)
def compile_yar_rules(source_dir: Path, compiled_dir: Path) -> None:
for filepath in source_dir.rglob("*.yar"):
filepath = Path(filepath)
create_dir_structure(compiled_dir, filepath)
compile_path = filepath
name_parent = compile_path.parent.name
if name_parent in compile_list:
saved_path = Path(compile_path.name)
else:
saved_path = Path(name_parent) / compile_path.name
compiled_filepath = compiled_dir / saved_path
with filepath.open("r") as yarafile:
print(filepath)
rules = yara.compile(file=yarafile)
rules.save(str(compiled_filepath))
for compile_folder in compile_list:
src = SOURCE_DIR / compile_folder
dst = COMPILED_DIR / compile_folder
compile_yar_rules(src, dst)
print(f"Compiled YARA saved: {COMPILED_DIR} = {compile_folder}")
At the and you have a yara-rules directory and scan your any malicious file via anoter simple Python script.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
import sys
from pathlib import Path
import yara
RULES_DIR = Path("/home/USER/yara-rules/compiled/python")
def load_rule_sets(rules_dir: Path):
rule_sets = []
for rule_path in rules_dir.rglob("*.yar"):
try:
rule_sets.append((rule_path, yara.load(str(rule_path))))
except Exception:
continue
return rule_sets
def extract_category(rule_path: Path) -> str:
for parent in rule_path.parents:
if parent.name in ("malware", "suspicious", "info"):
return parent.name
return "unknown"
def extract_family(rule_path: Path) -> str:
return rule_path.stem
def scan_file(sample: Path) -> None:
if not sample.is_file():
print(f"[!] Not a valid file: {sample}", file=sys.stderr)
return
rule_sets = load_rule_sets(RULES_DIR)
if not rule_sets:
print(f"[!] No YARA rules found in {RULES_DIR}", file=sys.stderr)
return
results = set()
for rule_path, rules in rule_sets:
try:
matches = rules.match(str(sample))
except Exception:
continue
if not matches:
continue
category = extract_category(rule_path)
family = extract_family(rule_path)
for m in matches:
results.add((category, family, m.rule))
print(f"File: {sample}")
if not results:
print("No matches.")
return
for category, family, rule_name in sorted(results):
print(f"[{category}/{family}] {rule_name}")
def main():
if len(sys.argv) != 2:
print(f"Usage: {sys.argv[0]} <file_to_scan>", file=sys.stderr)
sys.exit(1)
scan_file(Path(sys.argv[1]))
if __name__ == "__main__":
main()
When you run this script, the output will show you the matched yara rules in this format:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
python yara_scanner.py snake-golang/ed3c05bde9f0ea0f1321355b03ac42d0.bin
[info/compiler] Golang
[info/crypto] BASE64_table
[info/crypto] MD5_Constants
[info/crypto] RijnDael_AES
[info/crypto] SHA1_Constants
[info/crypto] SHA512_Constants
[info/fingerprint] EnumerateProcesses
[info/fingerprint] info_nop_sled
[info/library] DebuggerException__SetConsoleCtrl
[info/library] SEH__vectored
[suspicious/capability] command_and_control
[suspicious/evasion] ParentProcessEvasion
[suspicious/evasion] UNPROTECT_disable_process
[suspicious/evasion] win_token
[malware/ransomware] Windows_Ransomware_Snake_119f9c83
[malware/ransomware] Windows_Ransomware_Snake_20bc5abc
References
https://github.com/Neo23x0/YARA-Performance-Guidelines
https://github.com/Neo23x0/YARA-Style-Guide
https://cyb3rops.medium.com/improving-yara-rules-from-ta17-293a-dc9ab6e1818b
https://www.gendigital.com/blog/insights/research/yara-in-search-of-regular-expressions
https://en.wikipedia.org/wiki/Aho%E2%80%93Corasick_algorithm
https://www.intel.com/content/www/us/en/developer/articles/technical/introduction-to-hyperscan.html
https://github.com/avast/yarang
https://github.com/Neo23x0/yaraQA
https://www.nist.gov/itl/ssd/software-quality-group/national-software-reference-library-nsrl
https://virustotal.github.io/yara/
https://github.com/hasherezade/pe-sieve
https://www.nextron-systems.com/thor/
https://github.com/EgeBalci/amber
https://www.oreans.com/Themida.php
https://vmpsoft.com/
https://github.com/EgeBalci/deoptimizer
https://yarahq.github.io/
https://www.gendigital.com/blog/insights/research/yarang-reinventing-the-yara-scanner
https://virustotal.github.io/yara-x/